索引:存储引擎用于快速找到记录的一种数据结构.索引可以轻易将查询提高好几个数量级!最求极致!!!
索引基础
select uid from user where uid = 5;
- 上面的查询sql如果在user表上建立uid的索引,mysql会先在索引上按值进行查找,然后返回所有包涵该值的数据行。
- 如果索引有多个列,那么列的顺序很重要(最左前缀列匹配)。创建一个包涵两个列的索引和创建两个只包涵一个的索引是打不相同的。
索引的类型
索引有很多类型,mysql中索引是在存储引擎层实现的,所以不同的存储引擎索引的工作方式不尽相同。即使同种类型的索引在不同的存储引擎下实现也可能不同。
相信大家一定想过,既然Inndb是聚簇索引,那有索引再存储数据行是不是就数据重复了呢?能提出这个问题说明我们对索引有了进一步的思考。下面这个博文很好的解释了
B-Tree索引
大多数存储引擎都支持B+-Tree索引(B+树 叶子包含直接点指向下一个叶子节点的指针(由于数据都在叶子节点上,方便加载下一部分数据))
再强调下:
索引之所以能加快访问速度,是因为索引不在需要存储引擎进行权标扫描来寻找数据,取而代之的是从索引的根节点开始,利用索引的结构优化查询效率,最终要么找到对应的值,要么记录不存在
B+Tree的结构很适合范围查找所以基于磁盘阵列的数据库索引,可以一次加载一或一个扇区的数据对应树的一个节点。
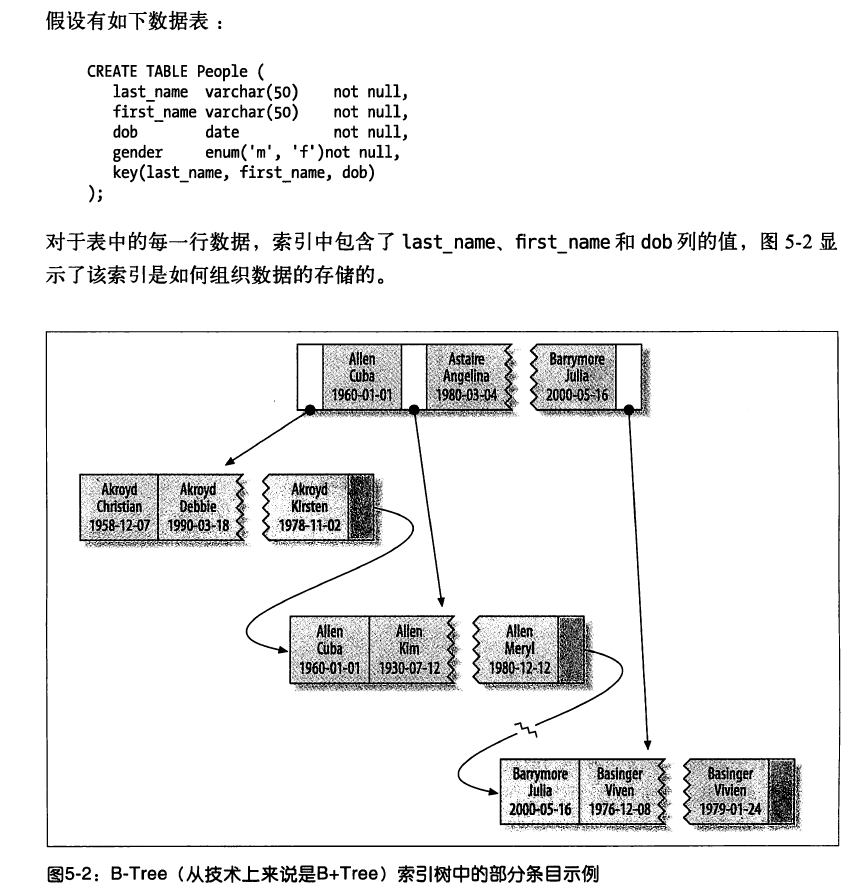
借用高性能mysql书中的一张图看下InnDB的索引存储结构,下图中建立了一个联合索引key(last_name,first_name.dob),对于表中的每一行数据索引中包涵了上面三个值,如下图优先使用lastname排序,在lastname相等的情况下用first_name排序,这种索引结构显然只能在匹配到索引的第一列的时候才能使用到到第二列索引,直接通过first_name查找是没办法使用索引的。
划重点:索引key的顺序很重要建立的时候要妥善考虑
B-Tree索引试用范围
B-Tree索适用于全键值、键值范围或键前缀查找。其中键前缀只适用于根据最左前缀的查找、
- 全值匹配:指的是和索引所有列进行匹配
- 匹配最左前缀:只匹配索引的第一列
- 匹配列前缀:匹配莫一列开头的部分,例如所有Y开头的last_name
- 精确匹配某一列并范围匹配另一列:例如匹配last_name:Li first_name:开头是X的人。
- 只访问索引的查询:访问只需要访问索引,而无须访问数据行。
因为索引树中的节点是有序的,所以出了按值查找外,索引还可以用于查询中的order by。同理只是用上面的查询类型
哈希索引(memroy 引擎)
哈希索引(hash index)基于哈希表实现。只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都回对所有的索引列一个hash code,hash code是一个较小的值。hash索引将所有的hash码存储在索引汇总同时在哈希表中保存指像每个数据行的指针。
空间数据索引
地理数据存储,mysql支持的不完善。可以使用PostgreSQL的PostGIS
全文索引
全文索引比较特殊,查找的是文本中的关键词,而不是直接比较索引中的值。全文搜索和其它积累索引的匹配方式不完全一样。有许多需要做一的细节,如停用词、词干和复数、布尔搜索等。全文索引更类似于搜索引擎做的事而不是简单的where条件匹配。
在相同的列上同时创建全文索引和基于值的B-Tree索引不会有冲突,全文索引适用于MATCH AGAINST操作,而不是普通的where条件操作。
索引的优点
索引不近可以快速的定位到表指定位置。索引还有一些其它的附加作用。
例如B-tree 由于索引是按照顺序存储的相同的索引值会放在一起索引也可以用于order by和group by操作。由于innddb索引里面存放啦实际的列值所以可以使用索引就完成全部查询。索引有以下几个有点:
- 大大减少服务器扫描的数据量
- 帮组服务器避免排序和临时表
- 将随机I/O年变为顺序I/o
划重点:索引可以带来高效的查找,但是同时也要维护特定的数据结构(根据索引的不同类型)这就回给插入和删除带来一定负担(例如b-tree的分裂算法等。中型到大型的表,索引就会非常有效,过少和过大建立和使用索引的付出和可能高于回报)
高性能的索引策略
要使用高性能索引首先要正确的创建。
独立的列
select user_id from user where user_id +1 = 5;
上面的查询语句是无法使用索引的要简化where使索引列单独的放在比较符号的一侧。
前缀索引和索引的选择性
引入一个概念索引的选择性,不重复的索引值/记录总数。索引的选择性越高则查询效率越高。唯一索引的选择性是1,这是最好的索引选着性,性能也是最好的。
在选择前最索引的时候,尽量让前缀接近当前列作为key的选择性。
创建前最索引,如下创建姓氏的前4个字节作为前缀的前缀索引Alter table user add key(lastname(4))
划重点:前缀索引更小更快可以(接近单列索引的选择性)但是前缀索引无法处理order by和group by也无法做覆盖扫描
全表扫描,全索引扫描和覆盖扫描的定义与区别见下面的blog
多列索引
常见的错误思维就是为每个列创建独立的索引或按照错误的顺序创建多列索引(个人觉得选择选择性越高的应该放到多列索引的越前面)
1 | create table t ( |
划重点:在一个查询中使用两个索引列,在低版本中可能会照成全表扫描,mysql5.0后查询会使用两个单列索引进行索引扫描并将结果合并
虽然上面的索引合并策略可以算作一重优化,但是也侧面说明了我们索引建立的十分糟糕
- 当出现你服务对多个索引做相交时(AND),通常以为要包涵所有相关列的多列索引,而不是多个单独的单列索引
- 当服务需要对多个索引做两盒操作时候,需要耗费大量的cpu和内存,在算法的缓存,排序和合并上,尤其是索引的选择选择性不高,合并后的量级就会很大,需要扫描返回的大量数据。
- 优化器不会极端到‘查询成本’,只关心随记页面的读取。有些情况倒不如使用权标烧苗或将查询改为union的方式。
通过expian如果看到索引合并,要重新评估下表的结构设计,或则通过参数金庸掉某些索引。
选择合适的索引顺序
上文面我提到选择选着性最高的防在索引最前列只是经验法则,还是要根据业务情况来判断,如何避免随记io和排序。
当不考虑排序和分组,业务大量查询时候,选择性最高的列放在前面通常是比较好的。同时在设计业务的时候也要注意一些特殊的逻辑,避免一个id有过多的行数,照成数据分布不均,影响索引使用的性能。