mysql的架构和历史
mysql最基本的架构图
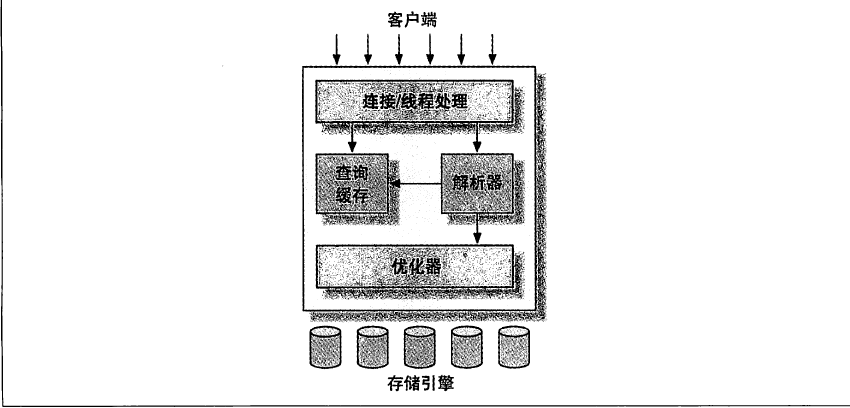
第一层:服务处理链接,授权和安全(一般服务都是如此架构)
第二层:是mysql核心部分,查询解析,分析,优化,缓存和内置函数包括存储过程,触发器,视图的等夸引擎操作都在这一层实现。
第三层:存储引擎层,只负责数据的存储和提取。服务通过API与存储引擎进行通信,使上层查询透明,eg:“开始一个事务”或则“根据组件提取一行记录”。存储引擎不解析sql,不同的存储引擎也不互相通信,简单的响应上层服务器的请求。
链接管理与安全性
链接管理
每一个客户端连接都会拥有一个线程,并使用线程池(mysql5.5)的方式,不用每次链接都创建或销毁线程
安全性
客户端链接到mysql的服务器的时候mysql服务器会进行认证,基于用户名,密码,原始主机信息,如果使用ssl的方式也会雁阵证书,同时服务还会继续验证客户端是否具有某个特定操作的权限。
优化执行
mysql会解析查询,并创建内部的数据结构(解析树),然后对其进行各种优化,包括重写查询,决定表的读取顺序,选择合适的索引。用户可以通过关键字提示(hint)优化器,影响他的决策过程。也可以请求优化器解释优化过程的各个因素,是用户知道服务器如何进行决策优化的,并提供一个产考基准,便于用户重构查询和schema,修改相关配置使应用尽可能的高效运转。
存储引擎对于优化查询有影响,优化器会请求存储引擎提供容量或某个具体操作的开销信息,表数据的统计信息等。
对于select语句,在解析查询之前服务会先检查查询缓存(query Cache),如果能找到对应查询,就不再执行查询解析,优化,执行的过程直接返回查询结果集合
并发控制
无论在什么,系统无论在何时,同一个时刻多个线程操作或修改同一份数据,都回引发并发控制问题。本小节学习和了解mysql在两个成名的并发控制:服务层与存储引擎层。通常处理并发我们是采用互斥锁的机制,但是锁相当于在只有一个进程可以处理该数据,这显然是把并发限定为顺序执行,对大型系统来说相当于在高速公路建了个收费站,很难受。
读写锁
如果换一种思想,“我就看看我不上手”,是不是就不会打扰“上手”修改的,你改你的我看我的。这里就是读/写锁(read lock / write loce)的思想 也是我们常说的共享锁(shared lock) 和排他锁(exclusive lock).使用读写锁可以保证只有写该数据的时候才阻塞其它的读锁和写锁。在只有读的情况下大家各自看各自的谁也不打扰谁
锁粒度
我们可以想一下我们的数据库可以有多个库,每个库有多个表,每个表有很多行数据,我们到底对什么粒度数据加锁呢?不用想很定时粒度约细冲突越少,但是需要锁的个数就越多。最理想的方式就是对修改的数据片进行精确的锁定,任何情况下锁的资源越少,冲突才会越少,并发才会越高。
另一个角度使用锁也是需要消耗资源的,位置锁内存,获得锁,检查锁的状态都是系统开销,如何找到平衡就是锁策略。
锁策略:在锁的开销和数据安全性之间寻找平衡。mysql 提供了跟多的选择,mysql存储引擎有自己的锁策略和锁粒度。mysql支持多个存储引擎的架构,所以不需要通用的解决方案。
表锁
表锁是最基本的锁策略,也是开销最小的锁策略,顾名思义就是锁定整张表。用户对该表进行写操作(插入,删除,更新等)需要先得到表写锁,同时阻塞所有其它用户对该表的读/写操作。对表的读是不阻塞的。
尽管存储引擎可以管理自己的锁,但是musql还会根据各种有效的表锁来实现不同的目的。例如服务器回味alter table等语句使用表锁,忽略存储引擎的标所机制
行锁
行级锁,因该是mysql最小的单元啦,如果粒度细致到行的column程度开销就太大啦。重所周知,(我之前咋不知道)innodb和xtradb一其它的一些存储引擎实现了行级锁,行级锁只在存储引擎层面实现,mysql服务器层并没有实现。